
Yet another server-managing experience
Writing this as a note to my future self

Part 1 : Connect
Pay for the server and then wait until the VPS is ready to use.
However, I had to contact customer service twice because the waiting process was excessively long. Surprisingly, there were still people who responded to my issue even though it was already night at that time.
Next, I've received the IP information and the root password. To connect using Putty, enter the IP address, and then click "connect". When prompted for the username, enter 'root', press enter. When prompted for the password, paste the root password (right-click), and then press Enter. You won't see anything on the terminal when you paste it (it's hidden anyway), but just trust it and press Enter after pasting.
Alternatively, if you're using Termux on Android, enter 'ssh username@ip' and provide the password when prompted.
Part 2 : Deploy
How do I send this bunch of source codes from my PC to this VPS?
Here what I did. Set up three git repositories: one for my PC, one on GitHub, and one on the VPS. Then, push the source code from my PC to GitHub and pull the source code from GitHub to the VPS.
Setting up a git repo on PC is easy; just use GitHub Desktop or something similar. Pulling a git repo from GitHub to VPS is also straightforward; just use 'git pull repo_url'.
The slightly challenging part is sending the repo back from VPS to GitHub. This is necessary when you modify the codes directly on the VPS to ensure the app is deployed correctly. In short, you need to create a specialized GitHub token for that.
To do this, log in to GitHub, click on "Settings," then "Developer settings," "Personal access tokens," "Fine-grained tokens," and finally, "Generate new token." Enter the one-time password code from your preferred authentication service. On "Repository access," choose "Only select repositories." Under "Account permissions," select "Contents," "Read and write." Generate the token and store it somewhere.
Back on the VPS, use the following commands: 'git add .', 'git commit -m "commit message"', and 'git push'. Use your GitHub username as the username and the generated token as the password. Done.
Part 3 : Monitoring
I love monitoring the httpd access log to see who the visitors to my server are. Are they actual humans? Bots? Search engine spiders? Script kiddies wannabe? Self-proclaimed 'security consultants' who knock down every open port on your server for the sake of whitehat hacking? Or is it a straight-up botnet trojan trying to take over the whole server? All of these questions could be answered by using this simple trick.
First, create a cronjob to archive the access.log once a day. I'm not entirely sure why, but the access.log on my server is cleared every 24 days, preventing access to the log well before that time. Hence, we need to copy it to another location just before it's routinely cleaned every day.
Execute "crontab -e" command, then add this line "0 23 * * * cp /var/log/apache2/access.log /var/log/apache2/$(date +\%Y\%m\%d).txt"
It means that every day at 23:00, a cronjob will copy the access.log file stored in /var/log/apache2 to a new file named CURRENTDATE.txt.
Finally, run this python script by using "nohup python3 thispythonfilename.py &".
Nohup, short for no hang up is a command that keep processes running even after exiting the shell or terminal. So this small python server could keep running even after you exit the console.
| import os | |
| from datetime import datetime, timedelta | |
| import re | |
| import mistune | |
| import web | |
| def merge_and_process_txt_files(directory_path): | |
| if not os.path.exists(directory_path): | |
| print(f"Directory '{directory_path}' does not exist.") | |
| return | |
| txt_files = [f for f in os.listdir(directory_path) if f.endswith('.txt') or f.endswith("ss.log")] | |
| if not txt_files: | |
| print(f"No txt files found in '{directory_path}'.") | |
| return | |
| all_lines = [] | |
| for txt_file in txt_files: | |
| file_path = os.path.join(directory_path, txt_file) | |
| with open(file_path, 'r') as file: | |
| all_lines.extend(file.readlines()) | |
| date_pattern = re.compile(r'\[([^\]]+)\]') | |
| ip_pattern = re.compile(r'(.*)\s\-\s\-') | |
| brack_pattern = re.compile(r'\"([^"]*)\"') | |
| themd = "Date | IP | HTTP | Useragent | Referer \n" | |
| themd = themd + " - | - | - | - | - \n" | |
| for line in all_lines: | |
| processed_line = line | |
| date_match = date_pattern.search(processed_line) | |
| date_str = date_match.group(1) | |
| log_date = datetime.strptime(date_str, '%d/%b/%Y:%H:%M:%S %z') | |
| new_date = log_date + timedelta(hours=7) | |
| ip = ip_pattern.search(processed_line) | |
| nyas = ["","",""] | |
| nyas = re.findall(brack_pattern,processed_line) | |
| #print(len(nyas)) | |
| if len(nyas) == 1: | |
| nyas.append("") | |
| nyas.append("") | |
| elif len(nyas) == 2: | |
| nyas.append("") | |
| themd = themd + str(new_date.strftime('%d %B %Y, %H:%M')) + " | " + str(ip.group(1)) + " | " + str(nyas[0]) + " | " + str(nyas[2]) + " | " + str(nyas[1]) + "\n" | |
| html_output = mistune.html(themd) | |
| return html_output | |
| def render(content): | |
| return f""" | |
| <html> | |
| <head> | |
| <title>File Viewer</title> | |
| </head> | |
| <body> | |
| <pre>{content}</pre> | |
| </body> | |
| </html> | |
| """ | |
| urls = ( | |
| '/', 'FileViewer' | |
| ) | |
| class FileViewer: | |
| def GET(self): | |
| return render(merge_and_process_txt_files(".")) | |
| class MyApplication(web.application): | |
| def run(self, port=8080, *middleware): | |
| func = self.wsgifunc(*middleware) | |
| return web.httpserver.runsimple(func, ('0.0.0.0', port)) | |
| if __name__ == "__main__": | |
| app = MyApplication(urls, globals()) | |
| app.run(port=9191) | |
Then access your.server.ip:9191
This script will read all the collected CURRENTDATE.txt access logs, merge them into one, parse their information, and neatly present it in a table using Markdown syntax.
If you only want to monitor today's log instead of all those collective logs, you can make a slight change to its code like this.
| import web | |
| urls = ( | |
| '/', 'FileViewer' | |
| ) | |
| class FileViewer: | |
| def GET(self): | |
| file_path = 'access.log' | |
| try: | |
| with open(file_path, 'r') as file: | |
| file_content = file.read() | |
| return render(file_content) | |
| except FileNotFoundError: | |
| return 'File not found.' | |
| def render(content): | |
| return f""" | |
| <html> | |
| <head> | |
| <title>File Viewer</title> | |
| </head> | |
| <body> | |
| <pre>{content}</pre> | |
| </body> | |
| </html> | |
| """ | |
| class MyApplication(web.application): | |
| def run(self, port=8080, *middleware): | |
| func = self.wsgifunc(*middleware) | |
| return web.httpserver.runsimple(func, ('0.0.0.0', port)) | |
| if __name__ == "__main__": | |
| app = MyApplication(urls, globals()) | |
| app.run(port=910) |
But this one will output a plaintext, not a markdown table like mon3.py.
Part 4 : (More) Monitoring
Plain access.log information is not sufficient for me; I need more details. Who is the IP that visited my server the most? What about their network information and geolocation? I require this information immediately.
First, open the output of mon3.py (the Markdown HTML table), copy its source code (inside the <table></table> tag only), and store it as a text file.
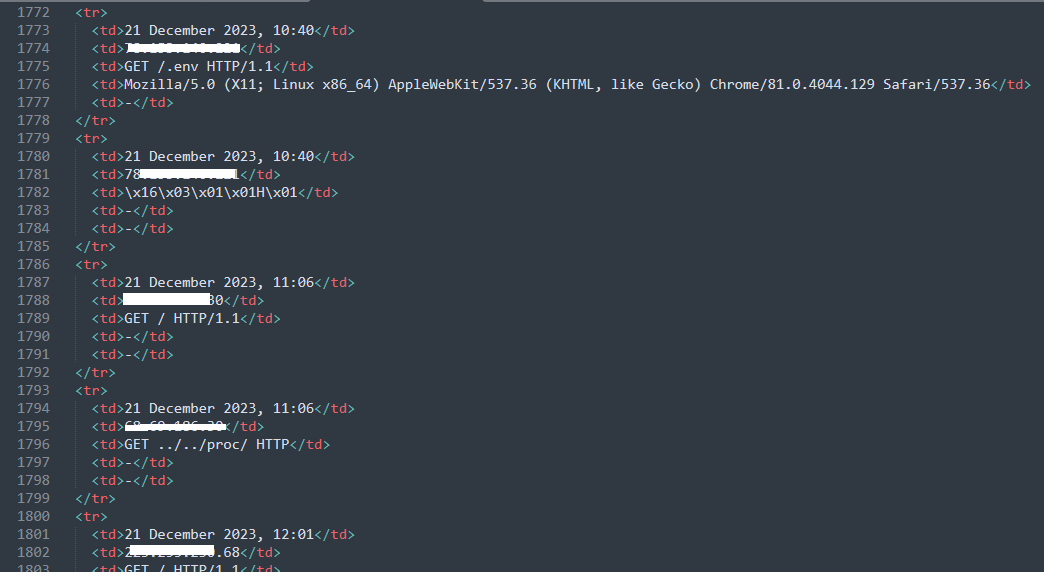
Then, execute this simple Python script to sort the IP addresses based on their frequency. Additionally, call the ipinfo API to geolocate each IP (you'll need to register on their site to obtain the access_token though).
| from bs4 import BeautifulSoup | |
| import ipinfo | |
| import pprint | |
| import sys | |
| import io | |
| sys.stdout = io.TextIOWrapper(sys.stdout.detach(), encoding='utf-8') | |
| access_token = 'INSERT_YOUR_TOKEN_HERE' | |
| handler = ipinfo.getHandler(access_token) | |
| # Read the HTML file | |
| with open('zumip.html', 'r') as file: | |
| html_data = file.read() | |
| soup = BeautifulSoup(html_data, 'html.parser') | |
| ipbag = dict() | |
| table_row = soup.find_all('tr') | |
| for x in table_row: | |
| cells = x.find_all('td') | |
| date = cells[0].text.strip() | |
| ip_address = cells[1].text.strip() | |
| request = cells[2].text.strip() | |
| user_agent = cells[3].text.strip() | |
| additional_info = cells[4].text.strip() | |
| if ip_address not in ipbag: | |
| ipbag[ip_address] = dict() | |
| ipbag[ip_address]['date'] = [] | |
| ipbag[ip_address]['date'].append((date,request,user_agent,additional_info)) | |
| ipbag[ip_address]['count'] = 1 | |
| else: | |
| ipbag[ip_address]['date'].append((date,request,user_agent,additional_info)) | |
| ipbag[ip_address]['count'] = ipbag[ip_address]['count'] + 1 | |
| sorted_dict_asc = dict(sorted(ipbag.items(), key=lambda item: item[1]['count'],reverse=True)) | |
| for i in sorted_dict_asc: | |
| print(i,"|",sorted_dict_asc[i]['count']) | |
| details = handler.getDetails(i) | |
| if "hostname" not in details.all: | |
| ho = "" | |
| else: | |
| ho = details.all['hostname'] | |
| print(ho,details.all['org'],details.all['city'],details.all['country_name']) | |
| print() | |
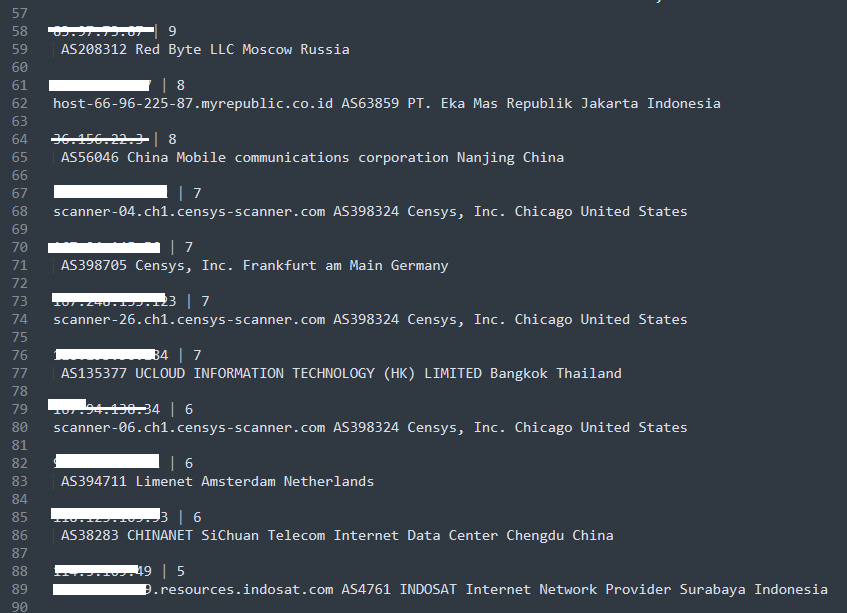
Here’s the result
Update
No need to manually cron the access-log. Try sudo nano /etc/logrotate.d/nginx and follow this documentation instead.