
Ctify_ v26.5.13
今回は日本語で何かを書いてみたい。
I once tried creating a wiki page whose title consisted entirely of kana characters.
At first, everything appeared to work correctly, although the system was clearly relying on some unusual internal behavior. Instead of storing the characters directly, PmWiki automatically converted the kana into HTML entities such as 霧 and 尾.
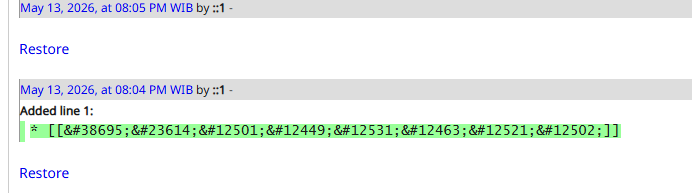
Most pages remained accessible without issues. However, a few pages behaved differently: clicking the generated link would redirect back to the homepage instead of opening the target page. The page became unreachable through normal navigation.
After tracing the issue, the root cause turned out to be character encoding.
By default, PmWiki is configured to use the ISO-8859-1 (Latin-1) charset.
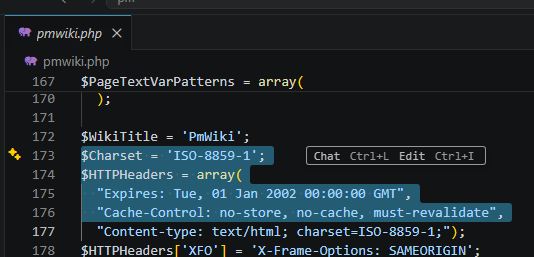
Since Latin-1 cannot represent kanji characters natively, the engine falls back to HTML entity encoding, which can lead to broken page resolution in certain edge cases.
The fix was surprisingly simple. Enable UTF-8 support by adding the following line near the top of local/config.php:
include_once("scripts/xlpage-utf-8.php");After switching the wiki to UTF-8 mode, kanji page titles worked normally without the entity conversion problems or broken redirects.
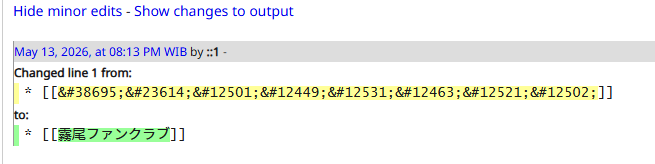
This bugfix is already shipped in ctify_ v26.5.13.
Appendix A : ISO/IEC 8859-1
The character encoding standard ISO/IEC 8859-1, commonly called “Latin-1”, is one of the oldest text encodings used on computers and the internet. It was standardized in 1987 as part of the ISO/IEC 8859 family. The goal was simple: represent Western European languages in a single-byte encoding system. Since computers at the time had very limited memory and bandwidth, using only one byte per character was extremely important.
Latin-1 uses exactly 256 possible values, from 0 to 255. The first 128 values are identical to ASCII, which means ordinary English text remains fully compatible. The upper half, from 128–255, contains accented letters and special symbols used in many European languages.
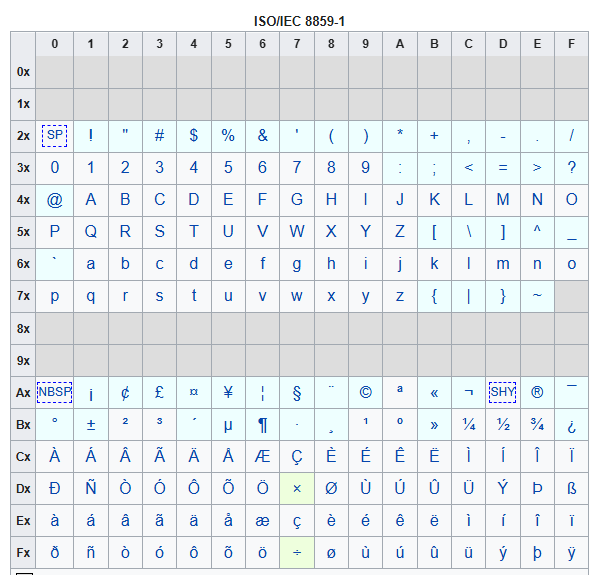
This made it suitable for languages such as : English, French, German, Spanish, Portuguese, Dutch, Danish, Norwegian, Swedish, and Icelandic. However, it could not represent many other writing systems. There was no support for :Japanese, Chinese, Arabic, Cyrillic, Thai, Hebrew, most African and Asian scripts. That limitation eventually became a major problem as the internet became global.
The byte range 128–159 in true ISO-8859-1 is mostly reserved for control characters, not printable symbols. But many operating systems, especially Microsoft Windows, used a slightly different encoding called Windows-1252. Windows-1252 placed printable symbols there instead, including euro sign, smart quotes, and em dash. This caused enormous confusion on the web during the 1990s and early 2000s. Many websites claimed to use “ISO-8859-1” while actually serving Windows-1252 text. Browsers became permissive and silently interpreted Latin-1 pages as Windows-1252 for compatibility.
Historically, Latin-1 became extremely important in early email systems, Usenet, HTML pages, UNIX systems, and HTTP protocols. For many years, Western-language websites defaulted to Latin-1 unless another encoding was specified. Eventually, Unicode and especially UTF-8 replaced Latin-1 almost everywhere. UTF-8 can represent virtually every writing system while remaining compatible with ASCII.
Appendix B : UTF-8
UTF-8 is only one member of a larger family of Unicode encoding formats. The most important ones are: UTF-8, UTF-16, UTF-32. All three encode the same Unicode characters. The difference is only how the characters are stored as bytes.
UTF-8 became dominant mainly because it solved several historical problems at once.
The biggest reason is ASCII compatibility. UTF-8 was deliberately designed so that ordinary ASCII text stays unchanged. The first 128 characters use exactly the same byte values as ASCII. That meant old software, network protocols, programming languages, UNIX tools, and internet infrastructure could gradually adopt Unicode without breaking everything.
For English-heavy text, UTF-8 is also space efficient. English letters still use only one byte each. In contrast: UTF-16 usually uses 2 bytes, UTF-32 always uses 4 bytes.
Another reason is byte order simplicity. UTF-16 and UTF-32 often have “endianness” issues. UTF-8 avoids this completely because it operates byte-by-byte.
UTF-16 still remains important internally in some systems. For example: Microsoft Windows APIs historically used UTF-16, Java internally uses UTF-16-style strings, JavaScript strings are UTF-16 based.
UTF-32 exists mostly for special situations where fixed-width characters simplify processing, but it wastes a lot of memory.
Unicode intentionally reserved a huge range of unused code points for future expansion. More than one million possible code points. Unicode also contains “Private Use Areas” (PUA), where organizations or communities can temporarily invent their own characters before official standardization. Some minority languages, fantasy scripts, or historical scripts used this approach before formal inclusion. Once Unicode assigns official code points, UTF-8 can encode them immediately without redesigning the encoding itself.
UTF-8 is not actually “8-bit fixed width.” The “8” in UTF-8 means it is built from 8-bit units (bytes), not that every character uses only one byte. UTF-8 is a variable-length encoding. Small code points use fewer bytes, while larger code points use more bytes. For example, ASCII letter “A” still just one byte. But Japanese あ is three bytes. And some emoji require four bytes.
JavaScript inherited much of its string model from the technological environment of the mid-1990s. Back then, Unicode was much smaller than today. Many engineers believed that 16 bits would be enough for all characters forever. So when JavaScript was created in 1995 at Netscape, UTF-16-style storage looked like a future-proof choice. Later, Unicode extended its maximum range. It exceeded what a single 16-bit value could represent. To solve this, UTF-16 introduced “surrogate pairs.” Characters above U+FFFF are encoded using two 16-bit code units.